

NVIDIA Launches Tesla K80, GK210 GPU

Kicking off today is the annual International Conference for High Performance Computing, Networking, Storage, and Analysis, better known as SC. For NVIDIA, next to their annual GPU Technology Conference, SC is their second biggest GPU compute conference, and is typically the venue for NVIDIA’s summer/fall announcements. Earlier we covered the announcement of NVIDIA’s role in the US Department of Energy’s latest supercomputer acquisitions, and today we’ll be taking a look at NVIDIA’s latest Tesla GPU compute card, Tesla K80.
At SC’13 NVIDIA introduced the Tesla K40, the first “fully enabled” Kepler Tesla card. Based on the GK110B variant of NVIDA’s GPU, this was the first Tesla product to ship with all 2880 CUDA cores enabled. Typically one would think that with a fully enabled GK110 based board that the Kepler Tesla lineup would have reached its apex, but for SC’14 NVIDIA will be pushing the performance envelope a bit harder in order to produce their fastest (and densest) Tesla card yet.
| NVIDIA Tesla Family Specification Comparison | ||||||
| Tesla K80 | Tesla K40 | Tesla K20X | Tesla K20 | |||
| Stream Processors | 2 x 2496 | 2880 | 2688 | 2496 | ||
| Core Clock | 562MHz | 745MHz | 732MHz | 706MHz | ||
| Boost Clock(s) | 875MHz | 810MHz, 875MHz | N/A | N/A | ||
| Memory Clock | 5GHz GDDR5 | 6GHz GDDR5 | 5.2GHz GDDR5 | 5.2GHz GDDR5 | ||
| Memory Bus Width | 2 x 384-bit | 384-bit | 384-bit | 320-bit | ||
| VRAM | 2 x 12GB | 12GB | 6GB | 5GB | ||
| Single Precision | 8.74 TFLOPS | 4.29 TFLOPS | 3.95 TFLOPS | 3.52 TFLOPS | ||
| Double Precision | 2.91 TFLOPS (1/3) | 1.43 TFLOPS (1/3) | 1.31 TFLOPS (1/3) | 1.17 TFLOPS (1/3) | ||
| Transistor Count | 2 x 7.1B(?) | 7.1B | 7.1B | 7.1B | ||
| TDP | 300W | 235W | 235W | 225W | ||
| Cooling | Passive | Active/Passive | Passive | Active/Passive | ||
| Manufacturing Process | TSMC 28nm | TSMC 28nm | TSMC 28nm | TSMC 28nm | ||
| Architecture | Kepler | Kepler | Kepler | Kepler | ||
| Launch Price | $5000 | $5499 | ~$3799 | ~$3299 | ||
Dubbed the Tesla K80, NVIDIA’s latest Tesla card is an unusual and unexpected entry into the Tesla lineup. For Tesla K80 NVIDIA has produced a new GPU – GK210 – and then put two of them into a single card. The net result is a card with no peers; NVIDIA has done dual GPU Tesla cards before (Tesla K10) and there have been dual GPU GK110 cards before (GeForce Titan Z), but nothing quite like Tesla K80.
From both a performance and power standpoint, NVIDIA is expecting to once again raise the bar. Factoring in GPU Boost (more on that later), Tesla K80 is rated for a maximum double precision (FP64) throughput of 2.9 TFLOPS, or a single precision (FP32) throughput of 8.7 TFLOPS. Compared to Tesla K40 this is roughly 74% faster than NVIDIA’s previous top-tier Tesla card, though GPU Boost means that the real performance advantage will not reach quite that high.

Fitting a pair of GPUs on a single card is not easy, and that is especially the case when those GPUs are GK210. Unsurprisingly then, NVIDIA is shipping K80 with only 13 of 15 SMXes enabled on each GPU, for a combined total of 4,992 CUDA cores enabled. This puts the clockspeed at a range of 562MHz to 870MHz. Meanwhile the memory clockspeeds have also been turned down slightly from Tesla K40; for Tesla K80 each GPU is paired with 12GB of GDDR5 clocked at 5GHz, for 240GB/sec of memory bandwidth per GPU. This puts the total memory pool between the two GPUs at 24GB, with 480GB/sec of bandwidth among them.
Meanwhile Tesla K80 will also be pushing the power envelope, again to get 2 GPUs on a single card. Whereas Tesla K40 and K20X were 235W cards, Tesla K80 is a 300W card. The fact that NVIDIA was able to get two high performance GPUs within 300W is no small achievement in and of itself, though for this reason GPU Boost plays a big part in making the overall product viable. Consequently energy efficiency gains are almost entirely reliant on what kind of performance Tesla K80 can sustain at 300W; the worst case scenario is that it’s only 2% more energy efficient than K40 while the best case is 59%, with the realistic case being somewhere in the middle.
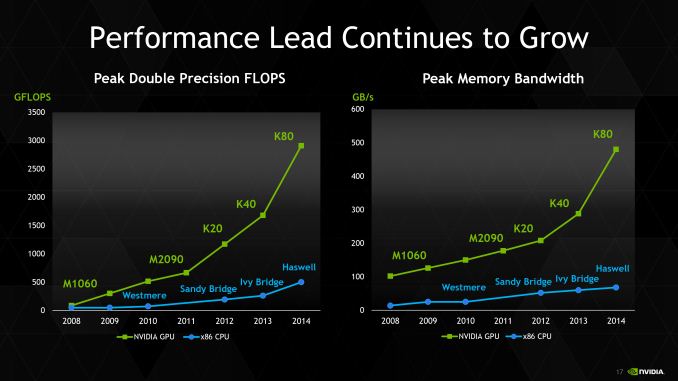
Speaking of efficiency, for Tesla K80 NVIDIA has crammed it into a standard size double-slot Tesla card enclosure, so on a volume basis Tesla K80 packs quite a bit more power per slot than K40, improving NVIDIA’s space efficiency. So far we have only seen passive cards, and given the need to move 300W of heat we expect that these cards will need to be passive in order to be paired up with appropriately powerful external fans.

Moving on, let’s start with GK210. Introduced with Tesla K80, GK210 is fundamentally the 3rd revision of GK110, following in the footsteps of GK110B, introduced on Tesla K40. Compared to GK110B, which was really just a cleanup of GK110, GK210 is a more radical alteration of GK110. This time around NVIDIA has made some real feature changes that although maintain GK210’s lineage from GK110, none the less make it meaningfully different from its predecessor.
| GK110 Family GPUs | |||||
| GK210 | GK110B | GK110 | |||
| Stream Processors | 2880 | 2880 | 2880 | ||
| Memory Bus Width | 384-bit | 384-bit | 384-bit | ||
| Register File Size | 512KB | 256KB | 256KB | ||
| Shared Memory / L1 Cache |
128KB | 64KB | 64KB | ||
| Transistor Count | 7.1B(?) | 7.1B | 7.1B | ||
| Manufacturing Process | TSMC 28nm | TSMC 28nm | TSMC 28nm | ||
| Architecture | Kepler | Kepler | Kepler | ||
| Tesla Products | K80 | K40 | K20/K20X | ||
To that end, while NVIDIA hasn’t made any sweeping changes such as adjusting the number of CUDA cores or their organization (this is still a GK110 derivative, after all) NVIDIA has adjusted the memory subsystem in each SMX. Whereas a GK110(B) SMX has a 256KB register file and 64KB of shared memory, GK210 doubles that to a 512KB register file and 128KB of shared memory. Though small, this change improves the data throughput within an SMX, serving to improve efficiency and keep the CUDA cores working more often. NVIDIA has never made a change mid-stream like this to a GPU before, so this marks the first time we’ve seen a GPU altered in a later revision in this fashion. That said, this also reflects on the state of the GPU market, and how Kepler will still be with us for some time to come.
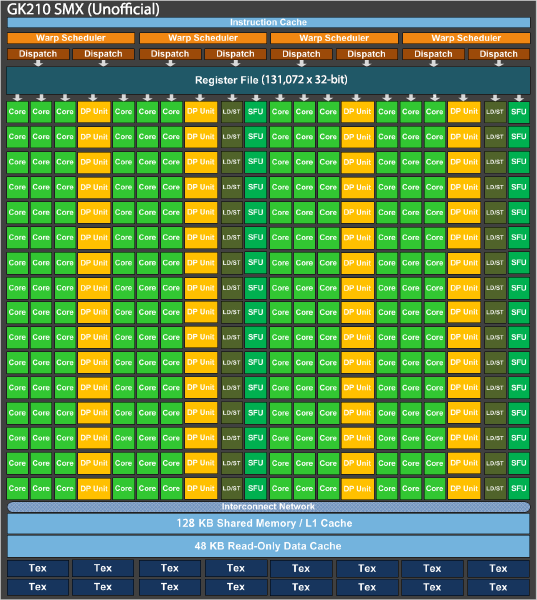
Overall I suspect that along with the memory change, NVIDIA has used this latest revision to once again tighten up the design of their HPC GPU to correct errata and reduce power consumption (thereby improving performance), which is part of the reason that NVIDIA is able to get two of these GPUs in a 300W card. Meanwhile GK210 will be in an odd place as it will likely be the first NVIDIA GPU not to end up in a consumer card; prior to this generation every GPU has pulled double duty as both a compute powerhouse and a graphics king. But with GM204 clearly ahead of GK110/GK210 in graphics, GK210 seems destined to Tesla cards and at most a Titan card for the budget compute market. Given the costs in bringing a new GPU revision to market – just the masks alone are increasingly expensive – the situation implies that NVIDIA expects to more than make back their money on additional sales enabled by GK210, which in turn indicates that they have quite a bit of faith in the state of the GPU compute market since it alone would be where the additional revenue would come from.
The final piece of the puzzle for Tesla K80 is GPU Boost. In the Tesla space NVIDIA introduced this on Tesla K40 in a far more limited implementation than on their consumer GPUs. Tesla K40 had to obey its TDP, but operators could select which of 3 clockspeeds they wanted, picking the one that comes closest to (but not exceeding) TDP for the best performance. However with Tesla K80 NVIDIA has now implemented a full and dynamic GPU boost implementation; just as in their consumer cards, the card will clock itself as high as the TDP will allow.
The change in implementation is no doubt driven by the more complex thermal environment of a multi-GPU card, not to mention the need to squeeze out yet more efficiency. As with consumer cards TDP headroom left on the table is potential performance wasted, and for Tesla this is no different. Without GPU boost and building to a worst case scenario, K80 would not be much more efficient than K40, as evidenced by the 562MHz core clockspeed. That said, with K40 NVIDIA made clockspeeds deterministic for GPU workload sync issues, so it’s not entirely clear why non-deterministic clockspeeds are now okay just a year later.
Specifications aside, Tesla K80 represents an unexpected evolution in Tesla designs. Strictly speaking, Tesla K80 is often but not always superior to Tesla K40. Per GPU throughput is lower than on Tesla K40, so given a task that doesn’t scale well over multiple GPUs a Tesla K40 could still be faster. None the less, the majority of tasks Tesla cards will run will cleanly scale well over multiple GPUs – this being a cornerstone of the modern HPC paradigm of clusters of processors – so outside of a few edge cases K80 should be faster, generally quite a bit faster.
Otherwise the density implications are quite interesting. A 300W TDP presents its own challenges, but in surmounting that it’s now possible to get 8 GK210 GPUs in a 1U form factor, which would put the FP64 compute throughput of such a setup at over 10 TFLOPS in 1U.

Wrapping things up, Tesla K80 will be a hard launch from NVIDIA and their partners, with individual cards and OEM systems equipped with them expected to be available today. Officially NVIIDA does not publish MSRPs for Tesla cards, but the first listings are already up. It looks like Tesla K80 is rolling out at $5000, which is actually a bit cheaper than the $5500 K40 first launched at (and now sells for $3900).
