Qualcomm Snapdragon 820 Experience: HMP Kryo and Demos

While the Snapdragon 820 has had a number of announcements about various aspects of the SoC, some details have been mostly left to the imagination. Today, Qualcomm held an event to release some details about Snapdragon 820, but also to show off what can be enabled by Snapdragon 820. Some of the main details released today include some estimates of power, and some additional disclosure on the Kryo CPU cores in Snapdragon 820.

In power, Qualcomm published a slide showing average power consumption using their own internal model for determining days of use. In their testing, it shows that Snapdragon 820 uses 30% less power for the same time of use. Of course, this needs to be taken with appropriate skepticism, but given the use of 14LPP it probably shouldn’t be a surprise that Snapdragon 820 improves significantly over past devices.
The other disclosures of note were primarily centered on the CPU and modem. On the modem side, Qualcomm is claiming 15% improvement in power efficiency which should eliminate any remaining gap between LTE and WiFi battery life.
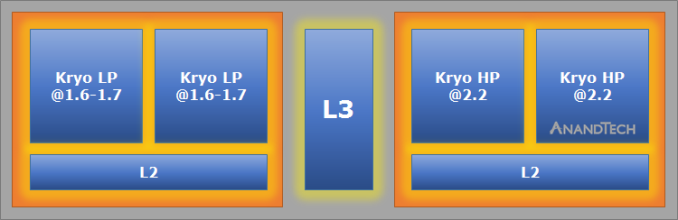
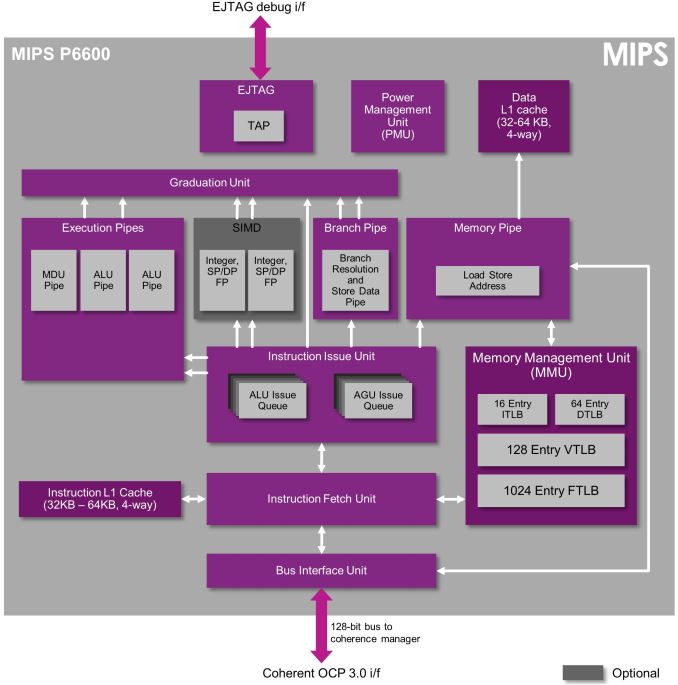
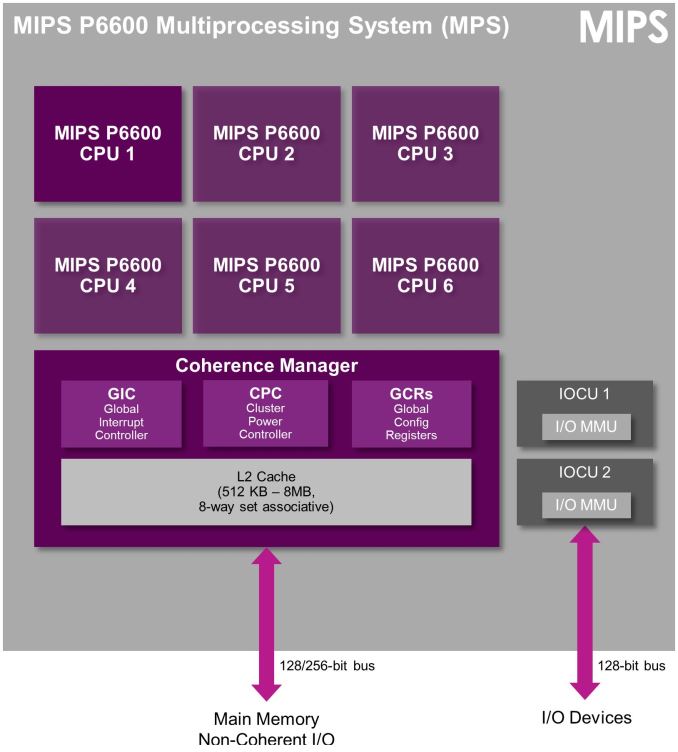
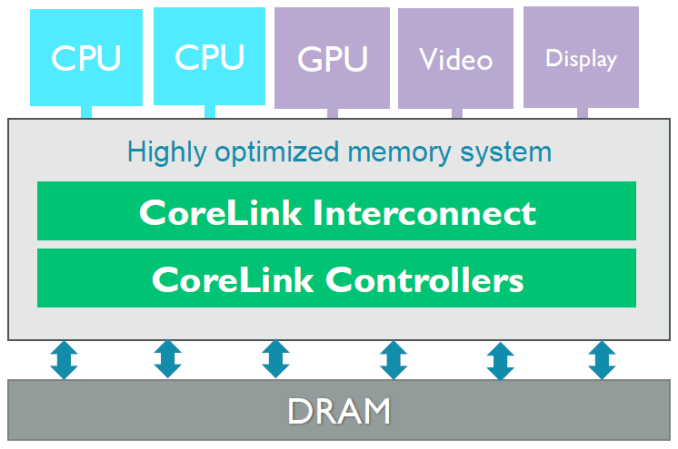
On the CPU side, while the claims of either doubled performance or power efficiency have been discussed before, new details on the CPU include that the quad core CPU is best described as an HMP solution with two high-performance cores clocked at 2.2 GHz and two low-power cores clocked at 1.6 or 1.7GHz when looking at previous Qualcomm SoCs with two clusters that share an architecture. Qualcomm also disclosed that the CPU architectures of both clusters are identical, but with differences in cache configuration. However, the differences in cache configuration weren’t disclosed. I wasn’t able to get an answer regarding whether this is an ARM big.LITTLE design that uses CCI-400 or CCI-500, but given that there’s an L3 cache shared between clusters it’s more likely that this is a completely custom HMP architecture.
In addition to these disclosures, we saw a number of demos. Probably the single most interesting demo shown was Sense ID, in which it was shown that fingerprint sensing worked properly through a sheet of glass and aluminum. To my recollection both the glass and aluminum were 0.4mm thick, so the system seems to be relatively robust. For those unfamiliar with Sense ID, rather than relying of high-resolution capacitive touch sensing the system uses ultrasonic sound waves to map the fingerprint, which allows it to penetrate materials like glass and metal and improves sensitivity despite contaminants like water and dirt.

One area of note was that Qualcomm is now offering their own speaker amp/protection IC that would compete with ICs like the NXP TFA9895 that are quite common in devices today. The WSA8815 chip would also be able to deliver stereo sound effects in devices with stereo front-facing speakers. It seems that the primary advantage of this solution is cost when bundled with the SoC, but it remains to be seen whether OEM adoption would be widespread.
One of the other demos was improved low light video and photos by using the Hexagon 680 DSP and Spectra 14-bit dual ISP. The main area of interest in this demo was improved visibility of underexposed areas by boosting shadow visibility, while also eliminating the resulting noise through temporal noise reduction.
On the RF side, in addition to showing that the Snapdragon 820 modem is capable of UE Category 12/13 LTE speeds Qualcomm also demonstrated that the Snapdragon 820 is capable of dynamically detecting WiFi signal quality based upon throughput and other metrics that affect VOIP quality and seamlessly handing off calls from WiFi to LTE and back. We also saw a demo for Qualcomm’s closed-loop antenna tuning system which allows for reduced impedance mismatch relative to previous open-loop antenna tuners which loaded various antenna profiles based upon things like touch sensing of certain critical areas.